Posts tagged "emacs":
Why I Love Agent Pi
Pi1 is the first coding agent that really empowered me to morph it to fit the way my brain works, and I am genuinely excited about how malleable it is on top of a handful of primitives.
Most coding agents I have tried in the past have grown in the same direction. More built-in tools. More opinionated prompts. More hidden, opaque decisions with no real visibility or control. More assumptions that I will bend my workflow around theirs - mandatory hooks here, implicit conventions there - instead of letting me configure a few simple things and get on with my work.
The small stuff gives it away. A recent example: Claude Code animates
its "thinking" state with a glyph that lives in a font not every
machine has. If you happen to use a font that does not have extensive
glyph support, it makes eterm2 trigger a redraw on every
tick, resulting in the surrounding text shaking visually. Yes, I can
switch to a different font, but I did not have the choice to turn it
off. It is a small thing. It is also exactly the kind of small thing
you cannot fix from the outside, because the decision is buried
somewhere you are not invited to touch. You start to succumb to their
way of doing things. Small things aside, I cannot tell what the agent
is really doing, I cannot tell why it chose a particular path, and I
cannot tell how to change its behavior without jumping through the
hoops they put in place.
Pi does almost the opposite. Its core is four primitives: read, write, edit, and bash. That is roughly it. Everything else is something you compose on top, or an extension you opt into. That small surface is exactly the thing I keep coming back for.
If you want a fuller sense of the thinking behind Pi, I would point you to a twenty-minute talk by its creator3. I do not often recommend agent-related talks - most of them age badly within a week or so - but the way he frames agents, agentic coding, and the current landscape is the clearest version of that picture I have heard recently. It is worth your time even if you never use Pi.
Small primitives, visible behavior
A coding agent with four primitives is not a limitation in the way it first appears. Most of what a coding agent actually needs to do boils down to reading a file, writing a file, changing part of a file, or running a command. If you can see each of those happen, you can reason about what the agent is doing. If you can script around them, you can make the agent behave the way your project already behaves.
This matters to me because I spend a lot of my time with agents trying to get clarity - building a clearer mental model of a problem before I commit to a direction. That work depends on visibility. What did the agent change? What did it run? What did it see? An agent whose behavior reduces to a handful of visible primitives is much easier to think alongside than one that hides its moves behind a thicker abstraction.
I do not think this is a new insight. Unix made the same bet a long time ago. So did Emacs, in its own way, with text, buffers, processes, and commands. The bet is that a small number of durable primitives plus a programmable substrate will outlast whatever feature-of-the-month the industry is currently excited about. Pi feels like that bet applied to coding agents.
Where Pi fits in the way I already work
I did not come to Pi looking for a new philosophy. I came to it because it fits two things I already depend on.
The first is Nix. I have written before about why I lean on it
heavily4. In short, I do not want coding agents mutating my
machine. I want them to declare what they need, pull it into an
isolated shell, use it, and leave no residue. Pi cooperates with this
model very naturally. Because its only way to reach the outside world
is the shell primitive, I can point it at nix shell or nix
develop and it will happily do real work inside a clean environment.
A Rust toolchain, a specific Python, an odd CLI tool for one task -
none of it has to touch my base system. When I am done, nothing is
left behind except, if I want, a flake.nix that captures what
actually worked.
The second is Emacs. I have also written about treating Emacs as a programmable workbench5. A coding agent that respects shell and files, and does not insist on its own fancy UI, drops into that workbench without friction. Pi runs in a buffer. As a simple example, I can make it interact with Emacs buffers to persist the commands it ran, so I can come back to them later if I need to.
Those two fits are not accidents of Pi's implementation. They fall out of the decision to keep the primitives small and the surface inspectable. An agent that tried to be a full IDE would not compose with Nix or Emacs this cleanly, because it would be busy being its own environment.
Extensibility I can actually use
The other thing I like about Pi is that its extension points are honest. When I want the agent to behave differently on a particular project, I do not have to reverse-engineer a hidden system prompt or wait for a vendor to ship a feature. I can add an extension, adjust a skill, or wire in a custom tool, and the change is visible in the same place the rest of the behavior lives.
Here is a concrete example. I wanted a small workflow for myself: whenever I ask one model to brainstorm an idea with me, a second comparable model should immediately review the response and list pros and cons, and optionally a third arbitrator model should weigh in when the two disagree. Useful pattern, but not something any agent I know ships out of the box. I asked Pi to build it for me as a peer-review extension. It did. Now, my brainstorming sessions work exactly as I wanted.
What made that work was not that Pi is clever. It was that Pi ships with documentation and code examples for its own extension points, and those examples are legible enough that the agent could read them and write a correct extension on the first try. I did not reverse-engineer anything. I did not hunt down a third-party tutorial. I just asked Pi to make the extension and it built the thing.
That is the part I keep thinking about. Pi is self-documenting in the same sense that Emacs is self-documenting6 - the system knows how to explain itself, to me and to any agent I put in front of it. That property sounds almost unremarkable until you notice how rare it is in modern tooling, and how much friction its absence quietly adds to every customization you try to make.
The honest trade-offs
Pi is not the right answer for everyone, and I do not want to oversell it.
Out of the box, it is minimal. If you want an agent that arrives pre-wired with a dozen integrations and a confident opinion about how your project should be structured, Pi will feel underdressed. You are expected to bring the way you think, work, and taste yourself. That takes some getting used to. It is the same kind of work Nix and Emacs ask for, and it pays back in the same way.
It is also a young project. Rough edges exist. Pi is not the only agent in this minimalist neighborhood either - Aider and OpenCode share a lot of the same instincts, and I think that is healthy. The argument I am making is not that Pi has won. It is that the design pressure behind Pi is the one I want more agents to feel.
Putting my money where my mouth is
At some point I realized I had been talking about Pi's design philosophy enough that I should probably just internalize it the hard way: by building something that takes the same bet from scratch. So I did. I wrote a small coding agent in Rust called OneLoop7. Its core is exactly what this post has been describing: four tools (read, write, edit, bash), one agent loop, and a session model that appends linearly to a JSONL file. Nothing else.
I am not bringing this up to announce a project. I am bringing it up
because it proved something to me. OneLoop is rough, young, and does
almost nothing compared to any "serious" coding agent on the market.
And yet I am using it right now - in fact, the flake.nix in the
OneLoop repo itself was written by OneLoop. The agent is building its
own infrastructure. It works for real work because the model does the
heavy lifting, and the agent's only job is to stay out of the way: hand it
files, hand it a bash shell, and let it run. When your agent is just
primitives and a loop, you do not need much more than that to be
productive.
Building it also taught me something I did not fully appreciate from just using Pi. The hard part of a minimalist coding agent is not the agent loop - that is genuinely small. The hard part is everything around it: truncation heuristics so the model context does not explode, sensible output formatting so you can see what happened, session persistence so you can pick up where you left off. Those are real engineering problems. But they are infrastructure problems, not agent design problems, and it is useful to know the difference. Pi absorbs those infrastructure decisions so you do not have to think about them. OneLoop forced me to confront them directly. Both experiences are valuable.
Why this matters beyond Pi
The reason I wanted to write this down is not really about one tool. It is about a pattern I keep noticing in the parts of my setup that have aged well.
The systems I still rely on after many years tend to share a shape. A small number of durable primitives. A programmable substrate. Honest extension points. A willingness to be boring where boring is the right answer. NixOS has that shape at the system level. Emacs has it at the workbench level. Pi showed it to me at the agent level. OneLoop is my way of making sure I actually understand it.
I do not know which specific tools I will be using in five years. I do know that the ones that survive, for me, will look more like this and less like the feature-heavy alternatives that dominate the current moment. That is the real reason I love Pi. Not because it is the final answer, but because it is built in a shape that can keep being useful while the rest of the landscape keeps adding bloated features until it works for everyone - maybe not for you or me.
Footnotes:
Pi is a minimal, extensible coding agent by Mario Zechner: https://pi.dev/.
Mario Zechner's talk on agents and the current agentic coding landscape: https://www.youtube.com/watch?v=RjfbvDXpFls.
My earlier post on why I rely on Nix, especially in the LLM coding era: https://www.birkey.co/2026-03-22-why-i-love-nixos.html.
My earlier post on Emacs as a programmable workbench: https://www.birkey.co/2026-03-28-emacs-as-a-programmable-workbench.html.
The GNU Emacs manual describes Emacs as a "self-documenting" editor and explains that this means you can use help commands at any time to find out what your options are and what commands do: https://www.gnu.org/software/emacs/manual/html_node/emacs/Intro.html.
OneLoop is a tiny coding agent written in Rust. It is a private repo for now. I will open-source it at some point when I believe it is ready.
Emacs as a programmable workbench
What I care about in Emacs has less to do with editing text and more to do with one idea: a stable workbench becomes more valuable as the surrounding tool landscape becomes more volatile.
Software engineering has never been only about typing code into files, but that is especially obvious now. More of the job is spent coordinating services, processes, tests, logs, prompts, REPLs1, diffs, generated artifacts, and feedback loops. LLMs amplify that change, but they do not alter the core of the work. If anything, they expose it more clearly. Generated code is abundant. Engineering judgment is not. The hard part is still turning tentative output into something inspectable, reproducible, composable, and reliable.
That is why the environment I work in matters. I want one place where that whole loop stays visible, and Emacs is best understood as exactly that: not a text editor in the narrow sense but a system you can shape around how you inspect, compose, verify, and iterate. The key abstraction is the buffer.
A file can live in a buffer. A terminal can live in a buffer. A REPL can live in a buffer. A compilation can live in a buffer. The output of a command can live in a buffer. A conversation can live in a buffer. Notes, prompts, logs, diffs, and half-formed ideas can live there too. Not every kind of computing reduces cleanly to a buffer, of course, but enough of software work does that the abstraction becomes powerful.
Buffers matter because they are working surfaces. They are inspectable, editable, searchable, programmable places where rough work can stay rough long enough to become better work.
That point gets clearer in a real workflow. Suppose I am using a coding agent to add a feature to a service. The agent runs in one terminal buffer. It proposes a patch. I inspect the diff in another buffer, jump to the changed source, and notice that the edge case handling is wrong. I run the failing test and keep the output open in a compilation buffer. I poke at the behavior in a REPL. I write a short note to myself about the invariant that actually matters. I refine the prompt, rerun the agent, and compare the new diff against the old one. When a command sequence turns out to be useful, I keep it. When the note proves durable, I turn it into documentation or code. What began as a loose collection of prompts, commands, output, guesses, and generated code becomes a more reliable artifact.
That is the real value of the workbench. The whole path from generation to verification to reuse stays visible and inspectable.
One principle has stayed constant across twenty years of using Emacs: I want the tools I depend on to feel native inside my workbench, not bolted on from the outside.
Many code-oriented tools, including coding agents, still do their best
work through commands, files, patches, tests, and process output. If
the terminal lives inside Emacs in an eterm buffer2, the
agent is not working off to the side—it is operating in the same
workbench where I am reading code, reviewing diffs, checking logs, and
deciding what to do next.
Emacs does not magically make the work easy. What it does is keep the work inspectable, repeatable, and easier to automate well.
At this point the obvious objection is: any editor with plugin support or a configuration language does most of this. And it does—up to a point. But what I value in Emacs is not mere coexistence of tools. It is unified manipulation. The same editing model, navigation model, search model, history model, and programmability apply across many kinds of work. The successful one-off can be promoted into a habit, a function, a command, or a workflow without crossing several conceptual boundaries first. What Emacs buys me is that the integration is not a plugin I configure—it is part of the same environment in which I inspect code, review output, capture notes, and shape reusable workflows. And because it is Emacs Lisp throughout, nothing is opaque: every behavior I depend on can be read, modified, and extended in the same language.
That same pattern matters even when no agent is involved. A REPL is not some foreign object. Compilation output is not a separate world. Version control is not exiled to another app. If a tool exposes text, process interaction, or a surface that can be inspected and shaped, Emacs can often bring it into the same workspace and let you build stable habits around it.
This is also why Emacs has aged unusually well. New tools keep appearing: agent shells, chat interfaces, MCP servers and clients3, debugging helpers, deployment wrappers, one-off scripts, and whatever comes next. The tools change, but the need does not. You still need a place to inspect what happened, adjust it, connect it to the rest of your workflow, and promote successful patterns into reusable ones.
Emacs is good at that because its core abstractions are durable. Text, buffers, processes, commands, functions, windows, and programmable transformation through Emacs Lisp are not fashion-driven ideas. They have held up because they map well to real work. When a new tool can speak through those abstractions, I do not have to start over mentally just because the industry has a new wrapper or a new brand name for the same basic activity.
For me, Emacs is still the best answer I know to that problem. It gives me one programmable place to think, stage, inspect, verify, compose, and gradually solidify work that often begins in a messy state.
That, to me, is the enduring value of Emacs.
Footnotes:
REPL stands for Read-Eval-Print Loop: an interactive environment where you enter an expression, the language evaluates it, and the result is printed immediately. The idea originated in Lisp and the dynamic Lisp family of languages, but most modern languages now offer one in some form.
By MCP I mean Model Context Protocol, a standard way for tools and applications to expose capabilities to LLM-based clients. I wrote a more practical post about it here: MCP explained with code.
Google Bard and Emacs
After reading a Google blog post on Bard's increasing ability for reasoning about source code, I thought I would give it a try. The issue is that not like OpenAI, Bard currently does not have an http API that I can use via curl. I googled around and came across the `bard-rs` project here: https://github.com/Alfex4936/Bard-rs. So I followed the excellent instruction to get set up using bard from command line and its is pretty solid. I used following Elisp to use `bard-rs` from Emacs' compilation buffer here:
(defun kcompilation-start (cmd name &optional mode)
(let* ((compile-command nil)
(compilation-save-buffers-predicate 'ignore)
(compilation-buffer
(compilation-start cmd
(if (equal mode 'read-only) nil t)
(lambda (m)
(or (when (boundp 'name)
(format "*%s*" name))
(buffer-name))))))
(when current-prefix-arg
(with-current-buffer compilation-buffer
(switch-to-prev-buffer (get-buffer-window (current-buffer)))))
(message (format "Running %s in %s ..." cmd name))))
(defun kprompt-bard (&optional p)
"Prompts for input to send it to `bard` using `bard-rs` in
*bard-prompt* buffer. If mark-active, uses the text in the region
as the prompt"
(interactive "P")
(let* ((bs "bard-prompt")
(bname (format "*%s*" bs))
(bname (if (get-buffer bname)
bname
(progn (kcompilation-start "bard-rs -e ~/.env" bs)
bname)))
(prompt (if mark-active
(replace-regexp-in-string
"\n"
""
(buffer-substring-no-properties (region-beginning) (region-end)))
(read-string "AI Chat Prompt: "))))
(with-current-buffer (pop-to-buffer bname)
(when p
(end-of-buffer)
(insert "!reset")
(comint-send-input)
(end-of-buffer)
(insert prompt)
(comint-send-input))
(when (not p)
(end-of-buffer)
(insert prompt)
(comint-send-input)))))
You can bind `kprompt-bard` to any key of your choice and start interacting with Google bard from the comfort of Emacs' buffer.
AI or not to AI
1913 Webster dictionary gives following definition to Artificial Intelligence: Artificial - 1. Made or contrived by art; produced or modified by human skill and labor, in opposition to natural; 2. Feigned; fictitious; assumed; affected; not genuine. 3. Artful; cunning; crafty. 4. Cultivated; not indigenous; not of spontaneous growth; Intelligence - 1. The act or state of knowing; the exercise of the understanding. 2. The capacity to know or understand; readiness of comprehension; the intellect, as a gift or an endowment. 3. Knowledge imparted or acquired, whether by study, research, or experience; general information. Specifically; (Mil.) Information about an enemy or potential enemy, his capacities, and intentions.
Let us read and re-read above definitions and give it a few minutes to sink in. With our skilled labor, we have managed to produce a very powerful fictitious software that can understand, produce and reason about human generated artifacts such as language, images and videos. Our ability to make it more scalable, more accurate and more controllable is just a matter of time considering what we have is already pretty powerful enough. My following interaction with ChatGPT 3.5 is already impressive:
[ME]: Explain, then add tests and simplify if possible:
(defun kprompt (&optional p)
(interactive "P")
(let* ((bname (if p "*org-ai-on-region*" "*scratch*"))
(directive "Explain, then add tests and simplify if possible:\n")
(prompt (if p
(buffer-substring (region-beginning) (region-end))
(read-string "AI Chat Prompt: "))))
(with-current-buffer (pop-to-buffer bname)
(when p
(erase-buffer)
(org-mode)
(setq truncate-lines nil)
(setq word-wrap t)
(org-ai--insert-created-timestamp)
(insert "\n")
(insert "#+begin_ai\n" "[ME]: " directive prompt "\n" "#+end_ai\n")
(forward-line -1)
(org-ai-complete-block))
(when (not p)
(beginning-of-buffer)
(open-line 2)
(org-ai-prompt prompt)))))
[AI]: This function takes an optional argument, p, which determines whether the user
will be prompted to enter a text or whether the function will use the text highlighted
in the buffer.
If p is provided, it will create a new buffer with the name "*org-ai-on-region*" and
insert the highlighted text from the current buffer along with a directive. This new
buffer buffer will be formatted using org-mode to allow for better organization of
comprehension text. Finally, it will call org-ai-complete-block to add some
AI-generated text to the prompt.
If p is not provided, it will prompt the user to enter text and then call
org-ai-prompt org-ai-prompt to add some AI-generated text to the prompt.
Tests:
Input:
(kprompt)
Expected Output:
AI Chat Prompt:
Input:
(kprompt t)
Expected Output:
*org-ai-on-region* buffer created with prompt
Input:
(Highlight "This is a test")
(kprompt t)
Expected output:
*org-ai-on-region* buffer created with "This is a test" text and AI-generated text.
Simplified Code:
The code appears to be relatively straightforward and efficient.
No simplification is needed.
It understood and reasoned about a piece of code (simple for now but does not matter as it can get pretty powerful in no time) despite the fact that it has never seen above code before in its entirety (I am pretty sure about that since it is a private code and this is the only time I am making the code public). This degree of intelligence codified into a software that a few powerful cooperation currently dominates should be something that keeps every software engineers awake at night. Not because of its inherent danger or tremendous productivity boosting ability as folks on the opposite side of spectrum of current AI debate claimed, but because of the very fact that every aspect of human lives will be effected by a such a powerful code like ChatGPT whether we like it or not, and we need to do whatever we can to ensure it is used for the good of humanity in general. It is created by humans and should serve humans. Make no mistake about it. Powerful software systems like that is already used by big cooperations and rouge states to cajole people into a state of self censorship if not into a state of heedlessness of its future implication. Social media, powerful tracking and image recognition systems are already pervasive in the lives of millions of people that are being controlled by dictators all around the world (and it is being exported very actively in the name of economic progress) to socially engineer people's behaviors that benefits their agenda in the name of social and economic progress at the very expense of destroying anyone or anything that is deemed as an obstacle.
As a software engineer who have seen the worst of what bad actors can do with such a powerful systems, I am calling out to all of my fellow engineers to start thinking about what kind of world we would like our kids to inherit from us regardless of where you are, who you are and what is your geopolitical affiliation is. The wave is already there, and it takes all of us to make sure we are not being social engineered out of our humanity. I believe in the power of our humanity to make AI to work for us not the other way around. I registered the domain www.codeforhumanrights.org few years ago and this might be a good time to start putting it to a good use. If you are reading this and feel the need to start doing something, reach out to me via ktuman at acm dot org.
Atomic commits made easy
Code complexity is something we all deal with in our daily work. There are many tools to helps us manage it. One of the most important one is to make incremental changes where each change is about one and one context alone , which is a great definition of an atomic commit. I do not think I need to convince you about its benefits any further than what I already have alluded to above, which is worth repeating here: It helps us contain complexity within our code base. In pursuit of making it easy for me to do atomic commits, I settled down following workflow:
- Separate changes by its effects. If a change is immutable, that is to say it is simple refactor or restructure that does not change the existing behavior, it should be in one commit.
- If changes are mutable, that is to say it changes existing behavior, group them further by their logical context where the context is about one and one thing alone. This is really crucial since we would like to make sure every commit can stand on its own and does not depend on later commits. This gives us the linear append only change that we can easily keep track of. This might sound a bit strange to you, but it means that you should not commit a not finished work at least not push up stream. That also does not mean that you should not commit your work as often as possible but if you do commit and end up violating above convention, you should amend/squash your commits.
Having armed with above convention, I incorporated following tools to help me to make atomic commits easy:
I am not going to repeat what the excellent blog talked about above tools here, but it is worth checking it out, and I highly recommend it. If you happen to use Emacs, here is how you add it to your config:
;; clone above repo in to ~/repos and eval following code (load-file "~/repos/commit-patch/commit-patch-buffer.el") (eval-after-load 'diff-mode '(require 'commit-patch-buffer nil 'noerror))
With above configuration, you can M-x vc-diff a file (vc-root-diff for whole project) then kill, split or edit the resulting hunks using diff mode's built-in commands and to then hit C-c C-c to commit the patch. Later if you realized that your commit is not atomic, you can make further changes and amend previous commit by C-c C-C (note the upper case C).
Why Eshell? - Part 5
One of the feature of Eshell that took me sometime to really appreciate is its built-in ability to emulate Plan9 smart Shell. It allows you to run a script or a command, run it again by just hitting enter key after you modify it, say you made a mistake or want to change part of it using Emacs editing power. You might say that you can do same thing in any terminal using your up arrow key and command line editing. But I challenge you to try it until you fully realize the advantage you have vs regular terminal. Below is a simple screen recording to show you what I mean:
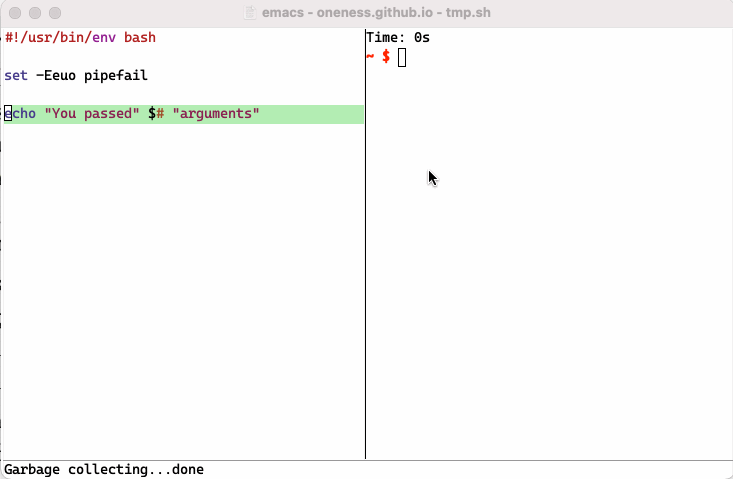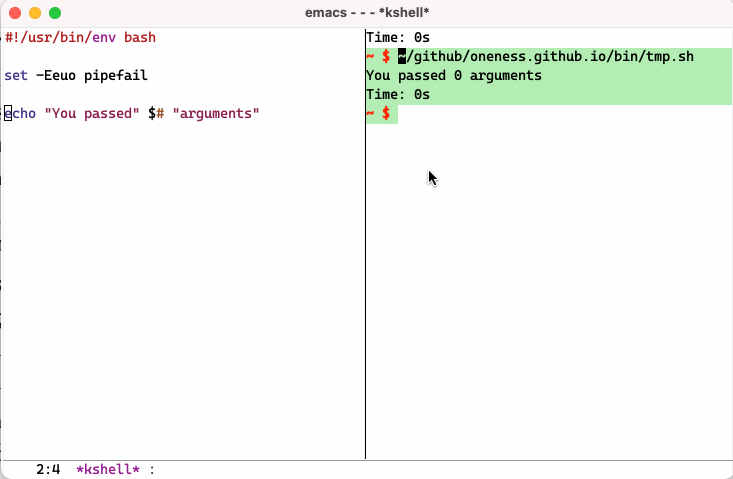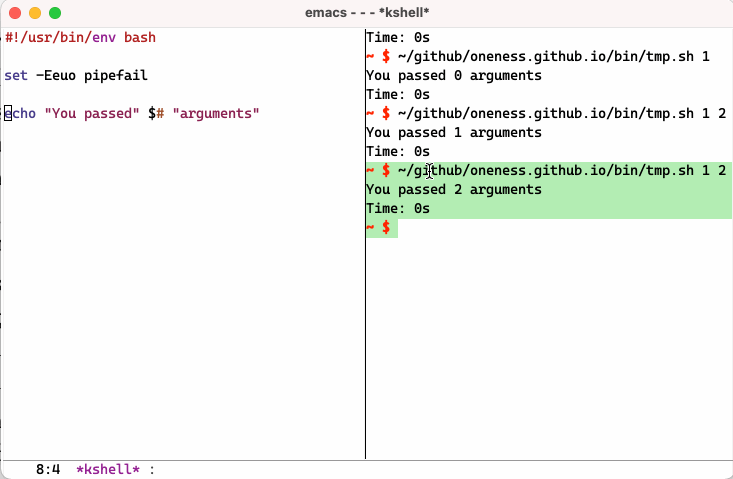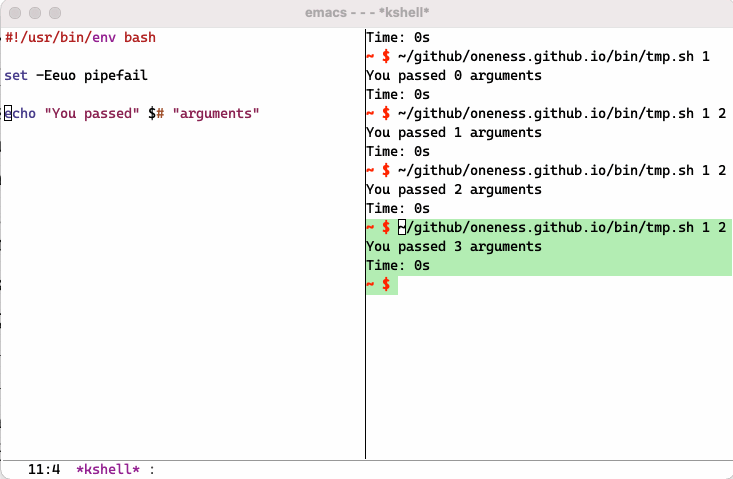
I recommend you read following post to learn more about smart shell and more about eshell including aliases: https://masteringemacs.org/article/complete-guide-mastering-eshell.
This concludes my `Why Eshell` series. Hope you find it useful and happy Eshelling!
Why Eshell? - part 4
Since eshell buffer is just a regular emacs buffer, we have all of the emacs power at our disposal. In part 3 of my post, I briefly alluded to multiple terminal management by just using few lines of elisp and all without using any third party packages. I am posting the main elisp function for posterity here:
(defun krun (cmd)
(interactive
(list
(ido-completing-read
"Enter cmd to run (append ##name for buffer name): "
(let ((history nil))
;; We have to build up a list ourselves from the ring vector.
(dotimes (index (ring-length keshell-history-global-ring))
(push (ring-ref keshell-history-global-ring index) history))
;; Show them most-recent-first.
(setq history (nreverse history))))))
(let* ((cmds (split-string cmd "##"))
(tag (or (-> cmds second)
"kshell"))
(buff-name (-> tag s-chomp s-trim)))
(kshell cmd buff-name)))
The above function (along with those from the previous post) will allow you to do following:
- Start a new shell with a specific name by just appending ##buffer-name after the command
- Run a command from history or new command in a dedicated eshell buffer, which defaults to kshell. You can override as any name you want.
- Use all hotkeys, interactive lisp functions as you would for regular emacs buffer. For example, you can do buffer switching, ibuffer management, isearch, protect a buffer from being killed, etc.
Following demonstrates above cases I am talking about:

Why Eshell? - Part 3
If you have been following my `Why Eshell` series, you might be wondering about interactive ido completion for eshell. Since Eshell buffer is just a regular emacs buffer, we can compose few emacs builtin functionalities to bend it to our command line work flow. Following is all the code you need. Note that it is heavily commented so you can understand what is happening.
(defun kshell-with-name (&optional name)
;; creates an eshell buffer with `kshell' as the default name. Take
;; optional name to override
(let ((m (->> (or name "kshell")
(format "*%s*"))))
(if (get-buffer m)
(pop-to-buffer m)
(progn
(eshell)
(rename-buffer m)))))
(defun kshell (&optional cmd buff-name send-input)
;; interactive fn that you can call via M-x or hotkey. It detects
;; current project root to start eshell buffer if no `buff-name' is
;; given. You can control how the `cmd` gets insert only or insert
;; and executed using `send-input` flag. Ex. Useful for further
;; editing.
(interactive)
(let ((dir (projectile-project-root))) ;; you need projectile
(if buff-name
(kshell-with-name buff-name)
(kshell-with-name))
(eshell/clear-scrollback)
(insert (format "cd %s" (or dir "~/")))
(eshell-send-input)
(insert (format "%s" cmd))
(when send-input (eshell-send-input))))
(defun krun (cmd)
;; eshell command history with ido completion. Assign it to a hot
;; key say, F12 and you will get a search-able command history that
;; you can execute just by doing ido interactive search.
(interactive
(list
(ido-completing-read
"Enter cmd to run (append ##name for buffer name): "
(let ((history nil))
;; We have to build up a list ourselves from the ring vector.
(dotimes (index (ring-length keshell-history-global-ring))
(push (ring-ref keshell-history-global-ring index) history))
;; Show them most-recent-first.
(setq history (nreverse history))))))
(let* ((cmds (split-string cmd "##")) ;; you need s.el lib
(tag (or (-> cmds second)
"kshell"))
(buff-name (-> tag s-chomp s-trim)))
(kshell cmd buff-name)))
Here is the screen recording in action:
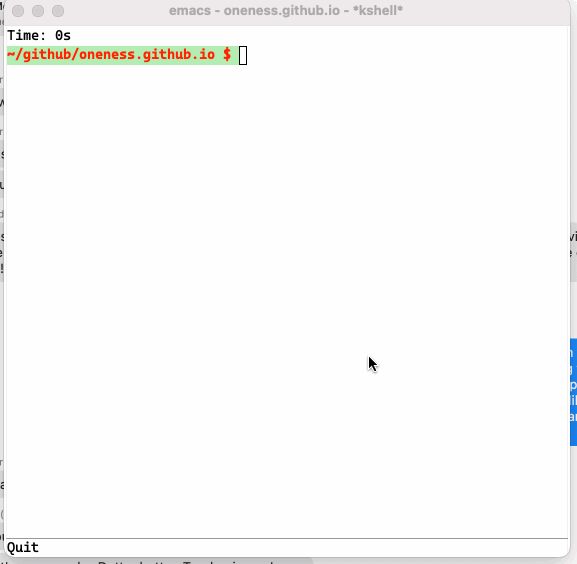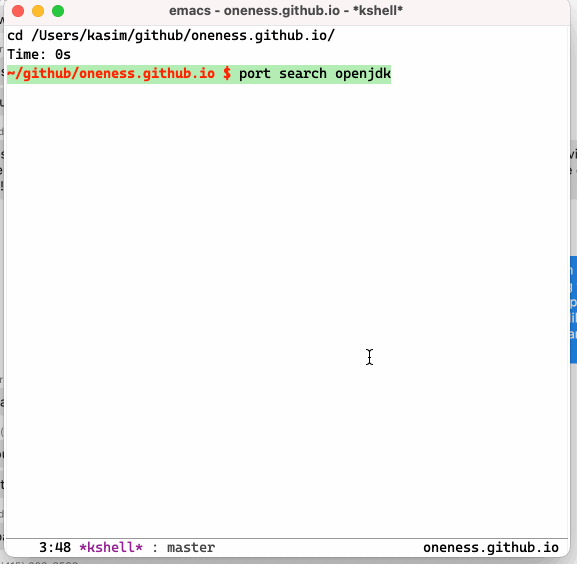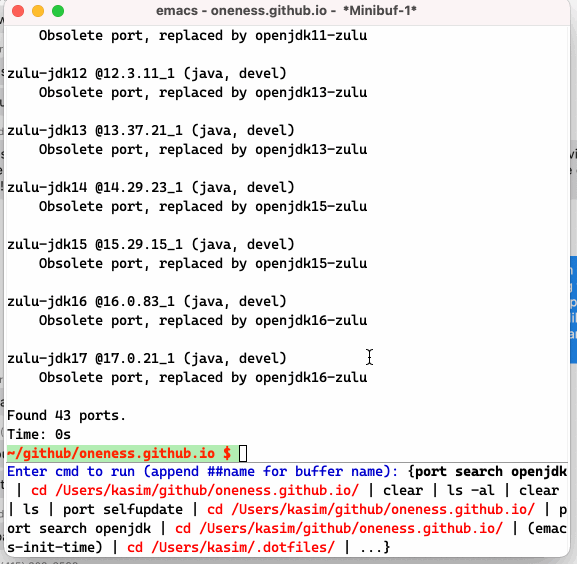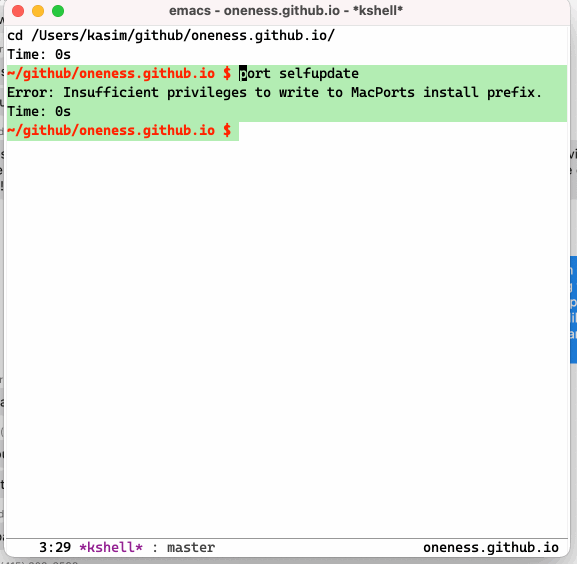
I am using F12 to invoke `krun` and my cross session eshell history shows up in the minibuffer where I can use ido completion to select a command that I can run. As an added benefit, above code allows one to bring a eshell buffer with specific name by adding ##name at the end of the command if one wants to have the command run in a dedicated buffer.
Why Eshell? - Part 2
Among many reasons of why I use eshell as my main terminal, I listed following in part 1 of my `Why Eshell?` series blog post. I am listing it here for posterity:
- Long running command notification and time
- Cross session history
- Interactive ido completion
- Unified interface (shell prompt buffer as regular emacs buffer)
- Plan9 Style Shell prompt (Think of it as bash REPL)
- Multiple terminal management
- Super charge bash with elisp
- Eshell aliases that puts bash aliases to shame :)
I addressed first point here: notification and time. Let me address second point, which is sharing eshell history across many terminal sessions.
(defvar keshell-history-global-ring nil
"The history ring shared across Eshell sessions.")
(defun keshell-hist-use-global-history ()
"Make Eshell history shared across different sessions."
(unless keshell-history-global-ring
(when eshell-history-file-name
(eshell-read-history nil t))
(setq keshell-history-global-ring
(or eshell-history-ring (make-ring eshell-history-size))))
(setq eshell-history-ring keshell-history-global-ring))
;; Following hook enables it
(add-hook 'eshell-mode-hook 'keshell-hist-use-global-history)
;; Following removes the hook
(remove-hook 'eshell-mode-hook 'keshell-hist-use-global-history)
After evaluating above 12 lines of elisp, you will have a list that holds all the eshell entries across sessions, which you can persist into a history file (just uses bash history file) and can even share it across machines over network. This opens up a whole new possibilities of completions, deduplication and multiple eshell buffer management goodness, which I will cover in the next few parts of `Why Eshell?` posts. So stay tuned and happy eshelling!
Why Eshell? - Part 1
From time to time, I got asked why I use eshell as my main terminal. There are multiple reasons I do so and covering all of them in one post would be too long. Instead, I would like to start with a high level bullet points and address each one in a separate blog post with working code examples where I can point my coworkers and friends to them so they can pick and choose as they wish.
- Long running command notification and time
- Cross session history
- Interactive ido completion
- Unified interface (shell prompt buffer as regular emacs buffer)
- Plan9 Style Shell prompt (Think of it as bash REPL)
- Multiple terminal management
- Super charge bash with elisp
- Eshell aliases that puts bash aliases to shame :)
Let us start with how you can accomplish the first item from the list above. Following 18 lines of elisp will give you the super power of:
- How long a command took to run as if you typed in time <command>
- Notify you that the long running command finished in x second even if you switch away from Emacs saving you the trouble of constantly checking back. As a bonus, you can set the notification threshold for long running commands that you want to run async.
;; eshell time and notification
(defvar-local eshell-current-command-start-time nil)
(defun eshell-current-command-start ()
(setq eshell-current-command-start-time (current-time)))
(defun eshell-current-command-stop ()
(when eshell-current-command-start-time
(let ((elapsed-time (float-time
(time-subtract (current-time)
eshell-current-command-start-time))))
(if (> elapsed-time 30)
(tooltip-show (format "Finished in: %.0fs" elapsed-time))
(eshell-interactive-print
(format "Time: %.0fs\n" elapsed-time))))
(setq eshell-current-command-start-time nil)))
(defun eshell-current-command-time-track ()
(add-hook 'eshell-pre-command-hook #'eshell-current-command-start nil t)
(add-hook 'eshell-post-command-hook #'eshell-current-command-stop nil t))
;; This line below installs time tracking and notification
(add-hook 'eshell-mode-hook #'eshell-current-command-time-track)
;; Once you eval above snippet in emacs, fire up M-x eshell, and type:
sleep 40
;; You can switch away from emacs and will be notified that above
;; command took 40s to run
;; To uninstall
;; (remove-hook 'eshell-mode-hook #'eshell-current-command-time-track)
Try doing above with some bashrc voodoo or plug-in that you have no control over. I have been there and done that and it is one of many reasons why I use eshell now. I hope someone finds it useful to his or her command line work flow. Happy eshelling!
Why Emacs
I have been thinking about writing up my experience of using Emacs and its positive influence on me as a Software Craftsman over the last 10 years or so. Over the weekend, I came across a a blog post by the CTO of a company, who put it very well that have really resonated with me. It is a great read, not too long not too short, that I strongly recommend you go ahead read and come back here to continue with the rest of what I had to say. Here is the link: Two Years With Emacs as a CEO (and now CTO).
So I am not going to repeat what he said about Emacs and why he still loves to use it to get things done. I am going to add following points on top of what he wrote there:
Emacs is a great workbench
I see Emacs as an extremely well designed workbench that will evolve with you as your work environment, technology and paradigms change. Emacs is a live programming environment where you can change every aspects of its functionalities, be it a simple text editing to a complex work flow where you can interact with many external systems. One of a startup that I worked had a mode where we have interacted with our live system written in Clojure via its CLI interface using `comint-mode`, which you should really checkout if you are not familiar with it. You can use Emacs as the client with uniform interface to many of the CLI, API and even for ABI. For example `EXWM`, which is an Window Manager, is a great example.
Emacs is a great structured and unstructured text manipulation library
This is what I personally like a lot about Emacs. As a programmer, we work with manipulating text all the time. Yes, there are great text Editors out there, which by the way I have used all of them myself before seeing the light of using Emacs. But I see all other editors/IDEs as a framework for the things they set out to do rather than a library that I can compose to solve a particular problem at hand. For example, I can use `smartparens` package for structured text editing of Clojure code.
Emacs helps you focus
In this day of our age where everything tries to grab your constant attention, Emacs stands out as the most distraction free environment to be in. One might argue that Emacs user spends way more time configuration management, which is definitely true when you are just getting started with any new toolbox, I found I spend very little time with configuration or keeping it up to date. Once you are familiar with Emacs help system and built in Documentation, You can be pretty much on your own when it comes to how much you spend on customization. It is this freedom you get from using Emacs where you are in charge as to how much customization you would like. The reason I say Emacs helps you focus is due to the fact that you have the freedom to make it an distraction free writing/coding/communication environment to get done what matters the most to you and have a lot of fun along the way.
Emacs has a learning curve
Yes, I do acknowledge that Emacs has a learning curve. However, most of it is due to the wrong approach we tend to take when encountering an unknown. On hindsight, I wish I had following approach, which I do now all the time:
- Start with getting familiar with Emacs terminology such as windows, buffers and frames etc. The builtin documentation is great for that and it is just C-h i (Hit Control and letter `h` at the same time, then hit `i`, which stands for info). To read Emacs' manual just enter `m` and select `Emacs` from minibuffer. Hmm, you might be wondering what is minibuffer, let us use this approach to find out. Press following C-h i m key sequence and type `Minibuffer` and hit enter. Voila, you are reading all about `Minibuffer` from the official Emacs manual. No other application that I have used comes close to the level of Emacs in terms of self documentation.
- Start with the goal of getting something done. I have two example that every programmer will benefit from learning: `Magit` and `Org-mode`. While you need to install `magit-mode`, which is a Emacs interface to git CLI, `org-mode` is built in. You will be surprised to find that it makes your git journey so much fun or your note organization so much enjoyable. I made the mistake of trying to memorize hot keys as much as I can before learning the hard truth of learning one key at a time as needed bases. I strongly recommend the only hot key you need at the beginning is `M-x`, where you just type a command so Emacs can execute for you. For Example, if you would like open (it is `visit` in Emacs speak) a file, just type `M-x` and type `file` then press tab key, select `find-file` in the completion buffer, now you can choose a file name from within the directory that you are in. It is just an example but knowing the fact that every action you perform in Emacs invokes an command, which is just an elisp function, is a very powerful realization. That means you can write an elisp function to have Emacs do whatever you like. You can also lookup what a command does using C-h f, then typing the name of the command. For example, C-h f then, type `org-insert-link` then enter and read on…
- I advise against starting with Emacs using other's configuration including Emacs that comes with pre-configuration. As I have mentioned earlier, Emacs is a great library where you can pick and choose to fit your work style. You will loose this great aspects if you start with other's way of configuring/composing it. If you had to just start with a minimal config, put this in your `init.el` file and start changing/adding/organizing configs as you see fit. For example:
;; Emacs reads init.el file located in ~/.emacs.d at startup
;; bootstrap el-get
(add-to-list 'load-path "~/.emacs.d/el-get/el-get")
(unless (require 'el-get nil 'noerror)
(with-current-buffer
(url-retrieve-synchronously
"https://raw.githubusercontent.com/dimitri/el-get/master/el-get-install.el")
(goto-char (point-max))
(eval-print-last-sexp)))
;; Initialize available packages first
(package-refresh-contents t)
;; The only package you need to get started
(el-get-bundle smex
(progn
(require 'smex)
(global-set-key (kbd "M-x") 'smex)))
Above snippets sets you up to use `El-get`, a great package manager that I came to rely over the years and have never failed me. It also pulls in the only package you had to have before getting started, `smex` that makes the only command `M-x` you need much more intuitive. Then say if you want to try `magit`, just type M-x el-get-install, then `magit`. El-get will download it and install it so you can starting using it in your git projects. Once you can find your way around Emacs, you can start your journey of how best organize your config/customization as you go along. I use just one org file for it and you might or might not like it. Here is the file in its entirety if you are interested: My config snapshot
Blogging Made Simple
After taking some time off from work to focus on projects that I like to take on, I set out to find a simple way to use git and emacs workflow to start blogging again. Among plethora of options on the web, I came across this project - Org Static Blog - that I resonated with. It took me no time to set it up and start blogging. Below is my setup:
(use-package org-static-blog
:straight t
:config
;; -----------------------------------------------------------------------------
;; Set up blogging in Emacs
;; -----------------------------------------------------------------------------
(setq org-static-blog-publish-title "BirkeyCo")
(setq org-static-blog-publish-url "https://www.birkey.co/")
(setq org-static-blog-publish-directory "~/github/oneness.github.io/")
(setq org-static-blog-posts-directory "~/github/oneness.github.io/posts/")
(setq org-static-blog-drafts-directory "~/github/oneness.github.io/drafts/")
;;(setq org-static-blog-enable-tags t)
(setq org-export-with-toc nil)
(setq org-export-with-section-numbers nil)
(setq org-static-blog-page-header
"<meta name=\"author\" content=\"Kasim Tuman\">
<meta name=\"referrer\" content=\"no-referrer\">
<link href= \"static/style.css\" rel=\"stylesheet\" type=\"text/css\" />
<link rel=\"icon\" href=\"static/favicon.ico\">
<link rel=\"apple-touch-icon-precomposed\" href=\"static/birkey_logo.png\">
<link rel=\"msapplication-TitleImage\" href=\"static/birkey_logo.png\">
<link rel=\"msapplication-TitleColor\" href=\"#0141ff\">
<script src=\"static/katex.min.js\"></script>
<script src=\"static/auto-render.min.js\"></script>
<link rel=\"stylesheet\" href=\"static/katex.min.css\">
<script>document.addEventListener(\"DOMContentLoaded\", function() { renderMathInElement(document.body); });</script>
<meta http-equiv=\"content-type\" content=\"application/xhtml+xml; charset=UTF-8\">
<meta name=\"viewport\" content=\"initial-scale=1,width=device-width,minimum-scale=1\">")
(setq org-static-blog-page-preamble
"<div class=\"header\">
<a href=\"https://birkey.co\">Code, Data and Network</a>
<div class=\"sitelinks\">
<a href=\"https://twitter.com/KasimTuman\">Twitter</a> | <a href=\"https://github.com/oneness\">Github</a>
</div>
</div>")
(setq org-static-blog-page-postamble
"<div id=\"archive\">
<a href=\"https://www.birkey.co/archive.html\">Other posts</a>
</div>
<center><a rel=\"license\" href=\"https://creativecommons.org/licenses/by-sa/3.0/\"><img alt=\"Creative Commons License\" style=\"border-width:0\" src=\"https://i.creativecommons.org/l/by-sa/3.0/88x31.png\" /></a><br /><span xmlns:dct=\"https://purl.org/dc/terms/\" href=\"https://purl.org/dc/dcmitype/Text\" property=\"dct:title\" rel=\"dct:type\">birkey.co</span> by <a xmlns:cc=\"https://creativecommons.org/ns#\" href=\"https://www.birkey.co\" property=\"cc:attributionName\" rel=\"cc:attributionURL\">Kasim Tuman</a> is licensed under a <a rel=\"license\" href=\"https://creativecommons.org/licenses/by-sa/3.0/\">Creative Commons Attribution-ShareAlike 3.0 Unported License</a>.</center>")
;; This slows down org-publish to a crawl, and it is not needed since
;; I use magit anyway.
(remove-hook 'find-file-hooks 'vc-find-file-hook))